이 포스트는 우아한형제들에서 2020년 우아한테크콘서트를 진행하며 이동욱님께서 발표해주신
수십억건에서 Querydsl 사용하기를 시청하며 학습하고 정리한 글입니다.
테스트 환경
Java : OpenJDK 1.8.0_252
Querydsl : Querydsl-JPA 4.2.1
Database : AWS Aurora MySQL 5.6 1.19.6
Querydsl의 Custom Repository를 사용하지 않는 방법
보통 Querydsl을 사용할 때
1. JpaRepository와 CustomRepository를 확장(extends)한 Repository Interface
2. Querydsl을 사용하는 메소드 시그니처를 정의하는 RepositoryCustom Inteface
3. 실제로 Querydsl을 사용하여 CustomRepository를 구현하는 RepositoryImpl Class
이렇게 3개의 파일을 이용하게 됩니다. 일종의 공식이라고 보면 되고, 이동욱님의 블로그에 자세한 설명이 나와있습니다.

Spring Boot Data Jpa 프로젝트에 Querydsl 적용하기
안녕하세요? 이번 시간에는 Spring Boot Data Jpa 프로젝트에 Querydsl을 적용하는 방법을 소개 드리겠습니다. 모든 코드는 Github에 있습니다. Spring Data Jpa를 써보신 분들은 아시겠지만, 기본으로 제공해
jojoldu.tistory.com
저도 실무에서 이 방법을 항상 사용해 왔었는데요. 엔티티가 늘어날 때마다 3개의 파일을 작성하는 것은 확실히 번거롭고 귀찮은 작업이었습니다.
해당 영상에서는 JPAQueryFactory만 있다면 Querydsl을 사용할 수 있다는 점을 해결법으로 제시했는데요.
@RequiredArgsConstructor
@Repository
public class BookQueryRepository {
private final JPAQueryFactory queryFactory;
public Optional<Book> findByIdx(Long idx) {
return Optional.ofNullable(queryFactory
.selectFrom(book)
.where(
book.idx.eq(idx)
)
.fetchOne());
}
}이렇게 idx를 통해 단건 Book 엔티티를 조회할 때, 해당 Repository는 별도의 인터페이스를 구현하지 않아도 Querydsl을 사용하여 조회할 수 있습니다.
언제 Custom Repository를 제거하면 될까?
이 방법의 단점은 상속으로 얻는 이점이 사라진다는 것입니다.
기본 repository와 Custom repository의 메소드를 하나의 인터페이스로 참조하며 사용할 수 없게 됩니다.
1개의 엔티티에 접근하기 위해 다수의 repository 인스턴스를 만들게 되는 것입니다.
따라서 특정 상황에서만 이 상속 구조를 제거하는 것이 필요합니다.
어떤 기능을 구현하기 위해 다양한 엔티티를 Join하여 함께 참조해야 하는데, 이걸 A엔티티 Repository의 역할로 봐야할지, B엔티티 Repository의 역할로 봐야할지 애매모호한 상황이 발생합니다. 저도 실무에서 심사와 심사 묶음 부분을 구현하며 관련 정보를 갖고 있는 엔티티를 가져올 상황이 있었는데, 메인 엔티티를 어떻게 결정해야 할 지 고민이 많았습니다.
이런 경우 특정 엔티티를 메인으로 하지 않는 기능이기 때문에, 위처럼 JPAQueryFactory만 주입받아 사용하는 Repository를 사용하면 좋습니다.
Querydsl의 다이나믹 쿼리 생성
querydsl에선 2가지 방법으로 동적 쿼리를 생성할 수 있습니다.
첫번째는 BooleanBuilder를 이용하는 방법입니다.
@RequiredArgsConstructor
@Repository
public class BookRepositoryImpl implements BookRepositoryCustom {
private final JPAQueryFactory queryFactory;
@Override
public List<Book> findBooks(String name, String author) {
BooleanBuilder builder = new BooleanBuilder();
if (!StringUtils.isEmpty(name)) {
builder.and(book.name.eq(name));
}
if (!StringUtils.isEmpty(idx)) {
builder.and(book.author.eq(author));
}
return queryFactory
.selectFrom(book)
.where(builder)
.fetch();
}
}BooleanBuilder를 이용하여 where절을 만들어갈 수 있습니다. 하지만 조건이 늘어날수록 if문이 많아지게 되고, 이 메소드가 어떤 쿼리를 사용하는지 한 눈에 파악하기 어려워집니다.
그래서 다른 방법으로 BooleanExpression을 사용할 수 있습니다.
@RequiredArgsConstructor
@Repository
public class BookRepositoryImpl implements BookRepositoryCustom {
private final JPAQueryFactory queryFactory;
@Override
public Page<Book> findBooks(Stirng name, String author, Pageable pageable) {
QueryResults<Book> book = queryFactory
.selectFrom(review)
.where(
eqName(name),
eqAuthor(author)
)
.orderBy(Book.updatedAt.desc(), Book.idx.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetchResults();
return new PageImpl<>(result.getResults(), pageable, result.getTotal());
}
private BooleanExpression eqName(String name) {
if (StringUtils.isEmpty(name)) {
return null;
}
return book.name.eq(name);
}
}이렇게 BooleanExpression을 반환하는 별도의 메소드를 사용할 수 있습니다.
where 절에 null이 들어가면 해당 조건은 자동으로 사용되지 않습니다.
단 모든 조건이 null이 되버리면 where절이 없어지면서 모든 row를 조회하기 때문에 주의해야 합니다.
일반적으로는 컨트롤러 단에서 validation을 하면서 파라미터가 없는 경우를 방지하기 때문에 쉽게 해결할 수 있습니다.
Select 성능 개선1 - exist 메소드 대체하기
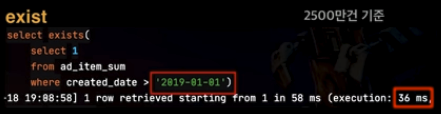
2500만건 기준으로 SQL의 exist 메소드를 사용하면 2.5초, count(1) 메소드를 사용하면 5초 정도가 걸렸다고 합니다.
전자는 조건을 만족하는 row를 찾으면 바로 종료해버리지만 후자는 찾더라도 총 개수를 카운팅하기 위해 모든 row를 탐색하기 때문입니다. 따라서 스캔 대상이 앞에 있을수록 성능 차이가 심해지겠죠?
그런데 Querydsl의 exist는 SQL의 exist를 사용하지 않고, 성능상 문제가 발생할 수 있는 count를 사용하여 수행됩니다.
문제는 SQL의 exist를 사용할 수 없다는 것입니다. 객체지향 쿼리 언어인 JPQL은 from 없이 쿼리를 생성할 수 없기 때문입니다. 위의 그림에서 보았던 select exists( )를 사용할 수 없어요.
그래서 조건을 만족하는 row를 1개라도 찾으면 바로 종료해버리는 쿼리를 직접 구현해야 합니다.
바로 limit 1로 조회를 제한하는 것입니다.
@RequiredArgsConstructor
@Repository
public class BookQueryRepository {
private final JPAQueryFactory queryFactory;
@Transactional(readOnly = true)
public Boolean exist(Long idx) {
Integer fetchOne = queryFactory
.selectFrom(book)
.where(
book.idx.eq(idx)
)
.fetchFirst();
return fetchOne != null;
}
}JPAQueryFactory의 fetchFirst는 제일 먼저 조회되는 하나의 대상을 반환합니다. limit(1).fetchOne()과 동일합니다.
조회 결과가 없으면 null을 반환하기 때문에, null 체크를 통해 엔티티 존재 여부를 반환할 수 있습니다.
Select 성능 개선2 - Cross Join 회피하기
일반적으로 Cross Join은 두 테이블의 나올 수 있는 모든 조합을 조회하기 때문에 성능이 좋지 않습니다.
그런데 JPA와 Querydsl을 사용하면서, 명시적으로 Join하지 않고 where절의 동치로 묵시적 Join을 하는 경우 Cross Join이 발생합니다.
사실 이는 Hibernate의 이슈이기 때문에 Spring Data JPA를 사용하는 이상 어쩔 수 없습니다.
따라서 다음과 같이 명시적 Join으로 Cross Join을 방지하면 됩니다.
@RequiredArgsConstructor
@Repository
public class BookQueryRepository {
private final JPAQueryFactory queryFactory;
@Transactional(readOnly = true)
public List<Book> crossJoin() {
return queryFactory
.selectFrom(book)
.where(
book.idx.gt(book.lender.idx)
)
.fetch();
}
@Transactional(readOnly = true)
public List<Book> innerJoin() {
return queryFactory
.selectFrom(book)
.innerJoin(book.lender, lender)
.where(
book.idx.gt(book.lender.idx)
)
.fetch();
}
}
Select 성능 개선3 - Entity가 아닌 Dto를 사용하기
저도 Querydsl을 처음 사용할 때, 항상 Entity로 조회 결과를 매핑하여 사용해야만 하는 줄 알았습니다.
그런데 이 방법은 생각보다 성능상 단점이 많습니다.
1. 엔티티의 모든 컬럼을 가져오기 때문에 로직에서 사용하지 않는 불필요한 컬럼도 가져옵니다.
2. 영속성 컨텍스트의 캐싱 기능을 반드시 사용하게 됩니다.
3. @OneToOne 관계에 있는 엔티티의 정보도 울며 겨자먹기로 가져와야 합니다.
특히 저는 심사 조회 부분을 개발하며 OneToOne 관계에 있는 엔티티를 가져오느라 엄청나게 많은 수의 컬럼을 가져오게 되었고, 이런 불필요한 조회에 엄청나게 괴로워했었죠.
이 상황에 대해 해당 영상에선 용도에 따라 조회 쿼리를 생성하라고 조언합니다.
비즈니스 로직에서 실시간으로 엔티티 변경이 필요한 경우 Entity 조회를 사용하고
대량의 데이터 조회가 필요하거나 성능 최적화를 고강도로 하고 싶은 경우 Dto 조회를 사용하는 것입니다.
@RequiredArgsConstructor
@Repository
public class BookQueryRepository {
private final JPAQueryFactory queryFactory;
@Override
public Optional<BookDto> findBookDtoByIdx(Long idx) {
return Optional.ofNullable(queryFactory
.select(Projections.fields(BookDto.class,
book.name,
Expressions.asNumber(idx).as("idx")
))
.from(book)
.where(
eqIdx(idx)
)
.fetchOne());
}
}
name처럼 Book 엔티티의 일부 컬럼만을 조회할 수도 있고, idx처럼 이미 파라미터로 들어온 값은 asNumber와 같은 as 표현식으로 대체하여 SELECT문에 포함시키지 않을 수 있습니다.
@OneToOne처럼 Lazy Loading이 일반적으로 불가능한 연관관계를 갖는 엔티티 정보가 필요한 경우도 이로 해결할 수 있습니다. 연관 엔티티의 일부 컬럼만을 가져오는 것이죠.
@RequiredArgsConstructor
@Repository
public class BookQueryRepository {
private final JPAQueryFactory queryFactory;
@Override
public Optional<BookDto> findBookDtoByIdx(Long idx) {
return Optional.ofNullable(queryFactory
.select(Projections.fields(BookDto.class,
book.name,
Expressions.asNumber(idx).as("idx"),
lender.idx.as("lenderIdx") // BookDto 매핑 필드와 이름 매칭
))
.from(book)
.innerJoin(book.lender, lender)
.where(
eqIdx(idx)
)
.fetchOne());
}
}
추가적으로 이는 JPQL에서의 distinct에도 영향을 미칩니다. 객체지향 쿼리 언어에서 distinct는 엔티티의 중복을 제거하라는 뜻으로, SELECT 문에 선언된 Entity의 컬럼 전체가 중복 체크의 대상이 됩니다. 그런데 불필요한 컬럼을 제외하면 distinct의 대상이 최소화되겠죠?
Select 성능 개선4 - Group By 최적화
MySQL에서 쿼리가 인덱스를 타지 않았을 때, Group By를 실행하면 FileSort가 반드시 발생합니다. 그런데 정렬이 필요없는 경우에도 대량의 데이터를 정렬한다면 성능 손실이 크겠죠?
이를 해결하기 위해 MySQL에선 order by null을 사용하면 Filesort가 제거되는 기능을 지원합니다.
하지만 Querydsl에선 order by null을 지원하지 않기 때문에 exist 메소드처럼 우리가 직접 구현해야 합니다.
아래처럼 OrderSpecifier 클래스를 확장한 커스텀 클래스를 사용하면 됩니다.
public class OrderByNull extends OrderSpecifier {
public static final OrderByNull DEFAULT = new OrderByNull();
private OrderByNull() {
super(Order.ASC, NullExpression.DEFAULT, default);
}
}
// 사용
...
.orderBy(OrderByNull.DEFAULT)
.fetch();
또한 이동욱님은 조회 결과가 100건 이하의 소량인 경우 어플리케이션에서 정렬하는 것을 추천하고 있습니다.
일반적으로 DB의 자원보다 WAS의 자원이 훨씬 저렴하기 때문입니다. DB 인스턴스는 서너대를 사용할 때, WAS 인스턴스는 수백 대를 사용하는 것을 보면 알 수 있죠?
그리고 페이징일 경우엔 Order by null을 사용할 수 없습니다.
Select 성능 개선5 - 커버링 인덱스
커버링 인덱스란 쿼리를 충족시키는데 필요한 모든 컬럼을 포함하고 있는 인덱스입니다. 따라서 select / where / order by / group by 등에서 사용되는 모든 컬럼이 인덱스 안에 있습니다. 이는 페이징 조회 성능을 향상시키는 일반적인 수단입니다.
그런데 문제가 있습니다. JPQL은 from절의 서브쿼리를 지원하지 않기 때문에, from 서브쿼리를 사용하는 경우 커버링 인덱스를 적용할 수 없습니다. 따라서 우회할 방법이 필요합니다.
방법은 단순합니다. 조회 쿼리 하나를 2개로 쪼개는 것입니다.
커버링 인덱스를 적용하여 where절에 들어갈 Cluster Key(PK)를 조회하고, 여기서 얻은 PK들로 SELECT 컬럼들을 후속 조회하는 것입니다. 이동욱님의 테스트 결과, 1억건 기준으로 네트워크를 한 번 더 타는 것을 제외하면 성능이 크게 밀리지 않는다고 합니다.
이렇게 하나의 쿼리를 다수의 쿼리로 나누는 사고 방식은 상황에 따라 유용하게 사용할 수 있습니다.
위처럼 JPQL의 특징으로 사용이 불가능하거나, 많은 엔티티들이 엮여 있어 하나의 쿼리를 생성하기 어려운 경우가 있습니다.
애초에 서브쿼리는 성능이 좋지 않습니다. 이동욱님도 쿼리에서의 안티패턴이라고 생각한다 합니다.
그러므로 Join으로 해결하는 방법 / 어플리케이션에서 처리하는 방법 / 쿼리를 나누는 방법을 항상 염두에 두고 쿼리를 짜면 좋을 것 같습니다. 아래 링크에 Querydsl 서브쿼리 사용에 대한 자세한 설명이 나와있습니다.
[Querydsl] 서브쿼리 사용하기
안녕하세요! 이번 시간에는 Querydsl에서의 Subquery 기본 가이드를 진행합니다. 개인적으로 ORM을 사용하며, 객체지향적으로 엔티티가 구성되어있으면 서브쿼리가 필요한 일은 거의 없다고 생각하
jojoldu.tistory.com
Update 성능 개선 - Batch Update 최적화 (더티체킹 하지 않기)
JPA는 영속성 컨텍스트의 1차 캐시에 저장된 엔티티의 정보를 트랜잭션 커밋 직전에 비교(더티체킹)하여, 변경된 점이 있다면 Update 쿼리를 날리게 됩니다. 결국 대량의 데이터를 수정할 때 영속성 컨텍스트에 들어 있는 모든 엔티티의 변경사항을 체크하게 됩니
이렇게 되면 Querydsl의 update를 이용하여 더티체킹하지 않고 쿼리를 날릴 때보다 큰 성능 손해를 보게 됩니다.
이동욱님의 테스트 결과에서 1만건 단일 컬럼 기준으로 약 2000배 차이를 보였습니다.
다만 단점은 있습니다. 더티체킹을 하지 않았기 때문에, JPA에서 사용하는 캐시도 갱신되지 않습니다. 캐시를 사용하는 추가 로직이 있다면 캐시를 직접 갱신할 필요가 있습니다.
정리하자면 DirtyChecking은 실시간으로 비즈니스를 처리하거나, 소량의 데이터를 처리할 때 사용하고
Querydsl update는 대량의 데이터를 일괄로 업데이트 처리할 때 사용하면 좋습니다. 특히 JPA 캐시 갱신이 필요 없는 경우 말이죠.
핵심 메세지
JPA와 Querydsl은 객체 지향으로 짜여진 어플리케이션과 관계 중심의 RDB를 매핑해주는 중간 계층입니다.
결국엔 여기서 생성한 데이터베이스에 쿼리를 날리게 됩니다.
진짜 Entity가 필요한게 아니라면, Querydsl과 Dto를 통해 필요한 컬럼들만 조회하고 업데이트하는 것이 좋습니다.
Insert 성능 개선 - JdbcTemplate으로 Batch Insert 사용하기
JDBC는 rewriteBatchedStatements 옵션으로 Insert 합치기 기능을 제공합니다.
그런데 JPA에서 Id 생성 전략을 IDENTITY (AUTO_INCREMENT) 방식을 사용하면 Batch Insert가 비활성화됩니다.
새로 할당할 PK 값을 미리 알 수 없기 때문입니다 (DB에 INSERT되고 나서야 PK가 할당됨)
이는 Hibernate가 채택한 flush 방식인 'Transactional Write Behind'와 충돌이 발생합니다.
엔티티를 생성할 경우 INSERT 쿼리를 쓰기 지연 SQL 저장소에 모아놓았다가, 트랜잭션 커밋 직전에 한꺼번에 전송하는데 이 방식과 Batch Insert가 충돌할 수 있다는 것입니다. (근본적으로 왜 충돌이 발생한다는 것인지는 정확히 모르겠으나... Hibernate 측에서 그렇다고 하면 받아들이는 수 밖에)
따라서 IDENTITY가 아닌 SEQUENCE나 TABLE 방식을 사용하여 Batch Insert를 날리거나, JPA를 벗어나 JdbcTemplate의 batchUpdate을 사용하여 Batch Insert를 날리는 방법이 있습니다. 이동욱님은 후자를 추천하며, 아래 링크한 homoefficio님의 테스트 결과에서도 Jdbc 방식이 제일 빠른 속도를 보여줬습니다.
물론 단점은 있습니다. 문자열로 SQL 쿼리문을 작성해야 하기 떄문에 컴파일체크, 코드-테이블 간의 불일치 체크 등의 Type safe한 개발이 어렵습니다.
Batch Insert와 관련해선 homoefficio님의 포스트가 자세하게 설명해줍니다.
Spring Data에서 Batch Insert 최적화
Spring Data에서 Batch Insert 최적화Spring Data JPA가 안겨주는 편리함 뒤에는 가끔 성능 손실이 숨어있다. 이번에 알아볼 Batch Insert도 그런 예 중 하나다. 성능 손실 문제가 발생하는 이유와 2가지 해결
homoefficio.github.io
Insert 성능 개선 - Type safe하게 Batch Insert 사용하기
일반적으로 Querydsl이라 하면 JPA를 사용하는 Querydsl을 말하긴 하지만, 사실 Querydsl과 Querydsl-JPA는 다른 것입니다. JPA와 Hibernate의 관계처럼, Querydsl은 추상화된 계층이고, 이를 Querydsl-JPA가 구현한 것으로 JPQL을 사용하게 됩니다.
유사하게 Native SQL을 사용하는 Querydsl-SQL / Mongo Query를 사용하는 Querydsl-MongoDB / ES Query를 사용하는 Querydsl-ElasticSearch가 있습니다.
그렇다면 Querydsl-SQL을 사용하여 Type safe한 Native SQL을 사용할 수 있지 않을까요? Batch Insert를 사용하기 위해 도입했던 JdbcTemplate보다 안전하게 쿼리를 작성할 수 있지 않을까요?
물론 가능합니다. 하지만 테이블을 스캔해서 QClass를 생성하는 방식이라 만족해야 할 조건이 많습니다.
1. 로컬 PC에 MySQL을 설치하고 실행
2. Gradle에 로컬 DB 정보를 등록해서 flyway(DB Migration Tool)로 테이블 생성
3. Querydsl-SQL 플러그인으로 테이블 스캔
엄청 번거롭습니다. 그렇다고 해서 개발환경의 DB를 스캔하기에도 제약이 있습니다.
만약 개발 DB에 신규 컬럼을 반영하면 안 되는 상황일 땐 (ex. QA 진행중) 로컬에서 이 신규 컬럼을 이용하여 개발할 수가 없게 되겠죠.
테이블 스캔을 피하고, JPA처럼 어노테이션 방식으로 Querydsl-SQL QClass를 생성해주는 오픈소스 EntityQL이 존재하긴 합니다. 이를 적용하여 성능 상 얻을 수 있는 이점은 크지만, 단점도 많습니다.
1. Gradle 5 이상에서만 동작
2. @Column - name 속성을 설정해야만 QClass의 필드가 선언된다.
3. @Table - name 속성을 설정해야만 테이블을 찾을 수 있다.
4. int, double, boolean과 같은 primitive type 필드 사용 불가
5. Querydsl-SQL의 미성숙한 발전으로 불편한 설정 多
6. @Embedded 미지원으로 복합적인 필드 불가능
그리고 가장 큰 단점은 Querydsl-SQL의 미지원으로, 컬럼명과 필드명이 일치하지 않는 경우 이를 매핑하는 클래스를 직접 구현해야 합니다. 에컨대 컬럼명은 account_id, 엔티티가 가진 필드명이 accountId라면 자동으로 매핑되지 않는 것이죠. 기본적으로는 @Column의 name 속성으로 Insert 쿼리를 만들 수 없다는 것입니다.
결국 JdbcTemplate과 EntityQL은 서로 장단점이 명확합니다. 어느 한 쪽이 더 좋다 말하기 어렵기 때문에, 각자의 상황에 맞춰 나은 방법을 도입해야 할 것입니다.
eXsio/querydsl-entityql
QueryDSL EntityQL - Native Query builder for JPA. Contribute to eXsio/querydsl-entityql development by creating an account on GitHub.
github.com
마무리
끝으로 이동욱님은 3가지 사항을 강조하셨습니다.
1. 상황에 따라 객체지향 / 전통적 쿼리 방식을 골라 사용할 것
2. JPA / Querydsl로 발생하는 쿼리 한번 더 확인할 것
3. JPA와 DB 학습 양 쪽을 다 할 것
실무에서 JPA + Querydsl을 사용하며 발생하는 비효율(특히 OneToOne 엔티티 이 놈...)에 대해 많은 고민을 했지만 해결할 방법을 몰라 많이 괴로웠는데, 마침 적당한 시기에 해당 영상을 보게 되어 많은 도움을 얻었습니다. 특히 일부 필드만을 프로젝션하여 성능을 개선하는 방법을 바로 적용할 수 있었습니다.
그리고 최근 인프런에서 김영한님의 JPA 기초 강의를 들으며 학습 중인데, 강조하신 사항이 강의 내에서 전달되는 메세지와 닮아 역시 경력자들은 비슷한 깨달음을 가지고 있구나 하는 생각이 들었습니다. 강의가 끝나면 DB 학습도 병행해야 할 것 같습니다.
정리하는 데 시간은 오래 걸렸지만 Querydsl 사용에 많은 변화를 준 영상이었기에 뿌듯하긴 하네요!
'학습 > JPA' 카테고리의 다른 글
| [JPA] Open Session In View (OSIV) (0) | 2021.05.23 |
|---|
댓글